
健康意識が高まり、健康ニーズが多様化している。ゆえに生活者に寄り添ったソリューションの提供、予防や未病ケアを含めたトータルケアの実現を、健康ビッグデータを活用した解析にて目指しているが、そこで用いるデータは――
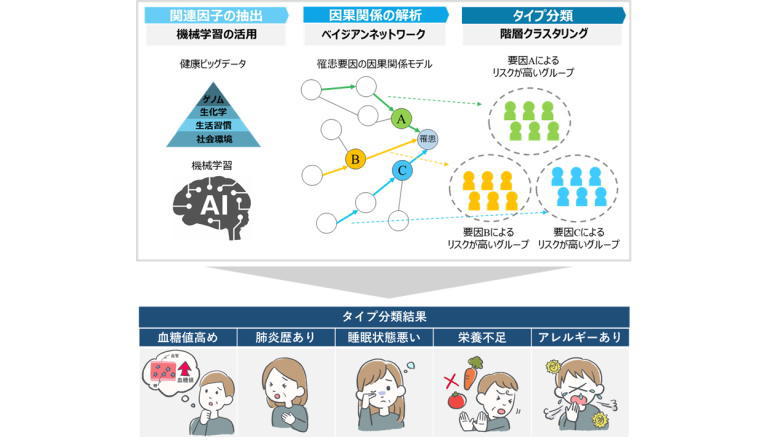
約3000項目×数千、数万人と膨大になり、一般的な相関解析やクラスタリング手法の適用だけでは特徴の抽出や、その関係性の把握が困難だったという。大正製薬は、京都大学大学院医学研究科(奥野恭史教授)および弘前大学との研究チームにより、インフルエンザをモデルとして健康ビッグデータから罹患リスクが高いグループを分類する、独自の層別解析手法を構築した。
弘前大学COI「岩木健康増進プロジェクト」の'19年度健診データ(flu罹患121名/1062名)を用いてインフルエンザ罹患をモデルとして実施。①関連因子の抽出:機械学習によって大量データから罹患関連因子を選抜。②因果関係の解析:当該因子について、ベイジアンネットワーク解析によって因果関係をモデル化。③タイプ分類:階層クラスタリングにて罹患リスクの高い特徴的なグループに分類。
上記3ステップでの解析の結果、血糖値が高めのグループ、肺炎歴があるグループ、睡眠状況が悪いグループなどの存在が示唆された。これら特徴の多くはインフルエンザを含む上気道感染症の罹患要因に関する先行研究と整合性がとれていて、今回の手法は有用だと考えられたという。同社は、この度の研究成果を第4回日本メディカルAI学会にて発表した。今後も多年度の健康ビッグデータの蓄積および解析手法の改良・検証を重ねていく。
さらには、かぜの罹患しやすさ、薄毛や白髪の要因、日常生活における疲労などに上記手法を応用することで、体質や健康リスクに寄り添った効果的な治療・予防に関する新たな知見を見出し、ソリューションを提供する。健康と美を願う生活者のより豊かな暮らしの実現に貢献していくという。