
高度にデジタル化された社会の実現が急がれている。今日、さまざまな場面で必要とされるAI処理システムの規模は毎年約10倍加し、1000億パラメーターの超大規模システムもすでに登場している。
AI処理システムは多数の電子演算回路で構築されていて、演算規模の拡大による消費電力や遅延の増加が著しい。エッジAIに適する小型化が困難だ。そこで、低消費電力・低遅延・大量データ処理が可能なAIアクセラレータの研究開発が進んでいる。その候補として、電子デバイスのスイッチングが不要で、パラメーター固定型の光集積回路に光を伝搬させるだけでよい「光ニューラルネットワーク演算」が注目されている。
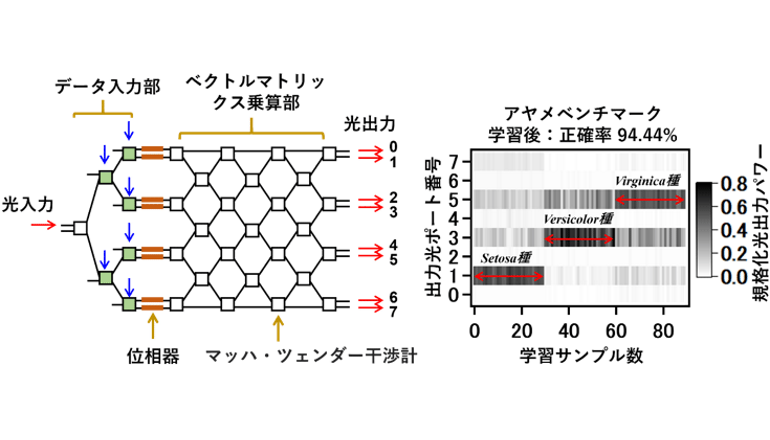
チップ内の光伝搬時間で演算が完了し、遅延は極小さい。同演算回路はしかし現在、光を用いた非線形性応答デバイスの集積が困難なため、光信号を電気信号に変換し、電子回路によるデジタル演算でこれを実現するハイブリッド構成となっていて、本来のメリットが生かされない。また、光演算回路の自律的な学習では、回路実機に対する直接学習が必要だという。
産総研PPRCの研究グループはNTTと共同で、JSTの支援のもと、電子回路ではなく、シリコン光集積回路を使った超低遅延かつ消費電力の少ないニューラルネットワーク演算技術を開発した。同技術では、解析すべき多次元データの電気信号は光集積回路の各入力ポートにて光信号に変換され、同回路に組込まれた多数の光干渉計を通過する際に演算が行われる。複数出力ポートの光強度分布として演算結果が出力される。
電子回路の千分の1以下の遅延時間、数十分の1の消費電力での演算が可能となり、10倍速超のクロック適用によりデータ処理量/時も大きくできる。AIアクセラレータへの応用が期待され、各種応用・実用領域への適合確認も進める予定だという。研究グループの成果は「Nature Communications」に掲載された。