
人の脳神経回路網を模した。ニューラルネットワークを多層に結合して、表現・学習能力を高めた機械学習手法のひとつ、深層学習を核とした人工知能(AI)の本格的な活用が期待されている。深層学習の性能を引き出すには、質・量を兼ね備えた学習データが不可欠である。
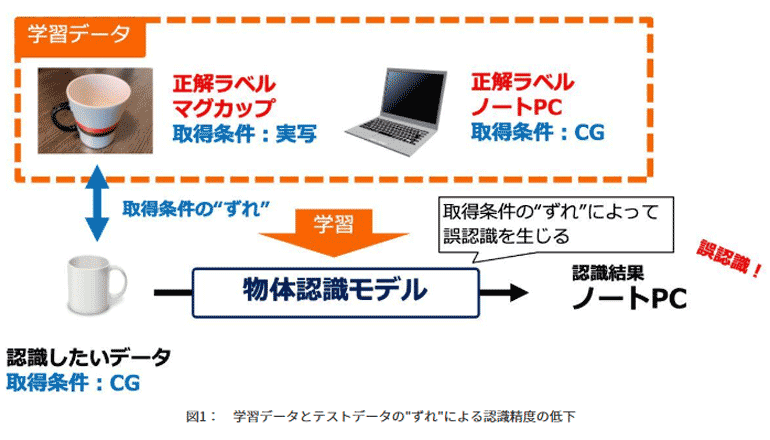
学習データと、試料/テストデータの取得条件(画像なら環境因子や撮影デバイス、制作・加工手段など)に"ずれ"がある場合、その認識精度が著しく低下する。AIの実用時、学習済み認識モデルにはさまざまな条件で取得されたテストデータが入力される可能性がある。"ずれ"をなくして、精度低下を防ぐには、認識モデルを学習する段階で、多彩な条件で取得した学習データを用いておく必要がある。
これまでの深層学習では、取得条件が異なる学習データが混在する場合に、高精度な認識モデルの学習が難しい。現実世界において、起こりえる取得条件を事前にすべて想定・把握できるとは限らない。例えば、医療・介護データのように、個人情報保護の観点から、取得条件の一部が削除されるような場合や、監視や点検、SNSのデータのように、各データの取得条件を把握することが極めて困難な場合などもある。
それらは、単に良質なデータを集めるだけでは解決が難しい技術課題であり、深層学習の利用拡大を妨げる要因になっていたという。NTTは、どのような条件で取得されたデータであるかがまったくわからない寄せ集めの学習データからであっても――データごとの取得条件の違いを教師なし学習によって推定することで、その影響を受けずに――高精度な認識モデルを学習可能な深層学習技術を世界で初めて実現した。
今回創出した、認識したい対象物体を判別不可能にするデータ拡張(新規データ生成)によって、取得条件の違いを分類する技術は、多くの映像情報メディアでの有効性が期待される。新たな領域でのAIサービスの実現を促進するだろうという。