
情報通信
産官学データの品質をアルゴリズム判定、相互利用や流通に活かす
情報を制するものは世界を制す。学術界でも産業界でもスポーツ界でも、はたまたより良い組織や社会を築くプロジェクトでも通用する金言における情報は、当世、デジタルデータである。コロナ禍でデジタル化の遅れが露呈した日本では今、"新しいデジタル・ニッポンのあり方 " が模索されている。
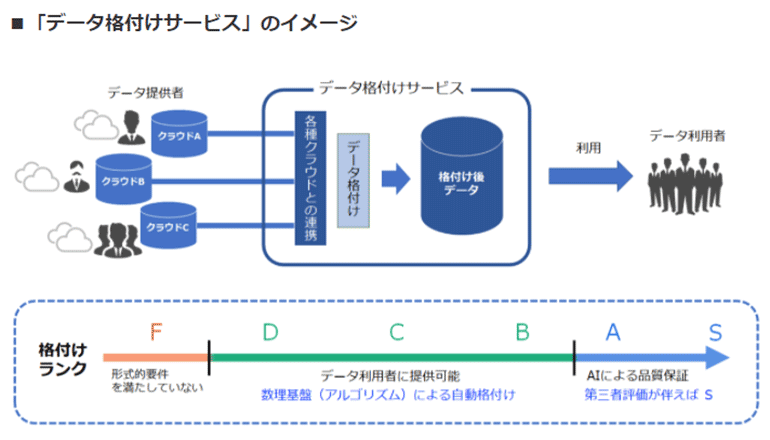
After/Withコロナ時代に、有効な方策を即実行、かつ即検証可能なデジタル資源の連携基盤が必要とされている。データ利活用に関してはその連携基盤上で多種多様なデータに格付けをする。データ格付けは多くの作業を自動で行う必要があり、優れたデータに関しては品質保証を行うための数理基盤も必須となり、数学に対する社会からの期待は極めて増大しつつある――
そこで今回、数理的特徴(満たすべきルール)による自動判定や、AI技術等による品質保証などの新しいデータ格付けのための数理基盤の構築を進めていくという。九州大学、ソフトバンクおよび豆蔵は今月、企業や自治体、教育・研究機関等で蓄積されているさまざまなデジタルデータについて、データの品質を数学的な理論を用いて客観的に判定し、格付けとして明示する「データ格付け」の実現に向けた共同研究を開始した。
数理基盤や理論の構築を来年1月まで、実証実験の環境構築を同年5月まで、実証実験の実施を同年7月まで予定している。3者は、「データ格付け」により産官学が保有するデータの品質を明確化することで、データの相互利用の促進や、データ流通市場の活性化を目指す。「データ格付け」の理論構築は九州大学と豆蔵が主担当となり、理論の実装および実証実験は、九州大学とソフトバンクが主担当として実施するという。
共同研究の幕開けに伴いオンライン(Zoom)にて、誰でもOK・参加費無料・定員500名の「デジタル・ニッポンの実現に向けたデータ格付け数理基盤に関するシンポジウム」が12月14日午後1時から開催される。