
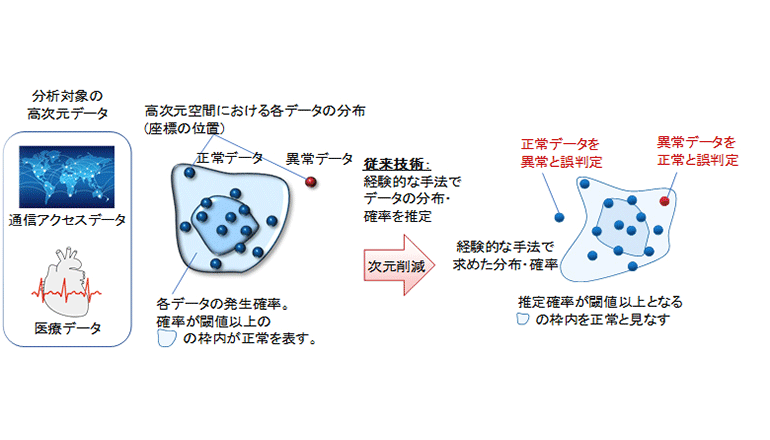
我々が暮らす3次元の空間のほか、点のみの空間である0次元、通信データのような数十次元、画像データのような数百万次元など、数学的にはさまざまな空間の広がりが考えられる。多くの業務で用いられるデータは、特徴量数が多い高次元データであり、データの次元数が増えると、データの特徴を正確に捉えるための計算の複雑さが指数関数的に増大してしまう、「次元の呪い」が広く知られている。
その回避方法として有望視されている、ディープラーニング(深層学習)を使って入力データの次元を削減する手法では、その後のデータ分布や、発生確率を考慮せずに削減していたため、データの特徴を忠実に獲得できておらず、AIの認識精度の限界や誤判定が発生する。これを解決し、高次元データの分布・確率を正確に取得することが、現在、AIによる高精度な検知・判断分野における重要な課題の一つになっているという。
富士通研究所は、高次元データの本質的な特徴量を正確に獲得するAI技術「DeepTwin」を世界で初めて開発した。分布・確率が未知の高次元データに対し、その次元をオートエンコーダ(教師無しの次元圧縮技術)で削減後、復元したときに双方のデータの劣化を一定値に抑えつつ、次元削減後の情報量を最小化したデータは、元の高次元データの特徴を正確に捉え、かつ次元を最小限に削減できていることを数学的に証明した。
高次元データの削除すべき次元数と削除後のデータの分布を制御するパラメータを導入し、圧縮後の情報量を評価項目に定め、ディープラーニングで最適化した。上述の数学理論に基づいて最適化されたときの次元を削減したデータの分布および確率は、データの特徴を正確に捉えられるという。技術の詳細は、7月12日から開催される機械学習の国際会議「ICML 2020」にて発表される。
今回の技術を、データマイニングの国際学会「KDD」が配布している通信アクセスデータ、およびカリフォルニア大学アーヴァイン校が配布している甲状腺数値データ、不整脈データを用いて異常検知のベンチマークテストをした。結果、従来のディープラーニングベースの誤り率と比較して最大で37%改善し、異なる分野の全データで、世界最高精度を達成した。
AIの根本的な課題を解く技術であり、幅広い分野でのAI適用を可能とする。「DeepTwin」は'21年度中の実用化が目指されていて、さらに多くのAI技術に適用されていくだろう。富士通はその成果を「FUJITSU Human Centric AI Zinrai」に活用していく考えだ。