
人が日常的に使っている言語をコンピュータで処理する。自然言語処理(NLP)技術の活用がビジネス界に広がりつつある。顧客コンタクトセンターでの1次受付、Webサイトのチャットボットなどから違和感をなくす基盤がNLPだ。
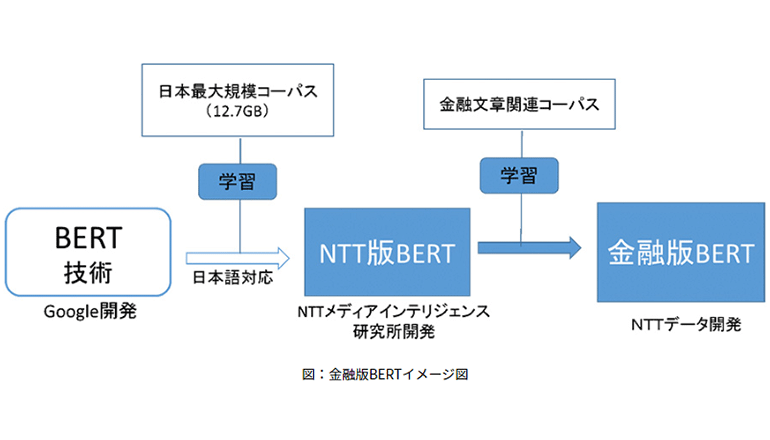
金融業界でもチャットボットによる顧客対応高度化や、審査支援等にそれが活用されているが、業界特有の用語や言い回しが多く、辞書整備や多数のルール構築を要する、NLPの適用には多大な労力と時間がかかっている。文脈を読める新NLPモデル――Googleが開発したBERTを適用するにしても、大規模なコーパス(言語資料の集合体)で学習させた日本語モデルはまだ少ないという(コーパス例@GitHub)。
NTTデータは10日、金融版BERTを用いた自然言語処理技術に関して、銀行や証券会社などの金融関連企業を募り、今月以降順次、実証を開始すると発表した。金融版BERTは、NTT版BERT(NTTメディアインテリジェンス研究所開発)にNTTデータが独自収集した金融関連文書を用い、金融文書向けに追加学習したモデルである。
金融専門用語や特有の文脈を含む文書を解析する際に、その都度言語モデルの学習を行う必要がなくなり、学習工程を短縮しつつ、高精度の結果を得ることが可能になる。その性能を評価するため、「金融文書における単語予測の正確性評価」と「金融系資格試験における得点比較」を行ったところ、NTT版BERTが大規模学習の効果を発揮、さらに金融版BERTは金融文書向けに適したモデルになっていることが確認できた。
従来のNLPでは難しかった文脈を踏まえた解析ができる。BERTの適用により、コールセンターにおけるFAQ回答引き当てや、営業日報からの情報抽出など、多様な処理の精度向上が期待できるという。同社は金融版BERTについて、今年度に5件の実証を行い、'21年度中にサービス提供を始める考えだ。