
各人に最適な治療法を提供する。個別化医療のひとつ、ゲノム医療では遺伝子情報に基づく療治や投薬が行われる。日本においても、がんを対象としたゲノム医療が保険収載のもとで昨年6月に開始された。がん細胞のゲノムを調べることによって、がんの原因となったゲノムの変異を突きとめる。
その情報からがんの弱点を見いだすことで効果が期待される薬剤を選択し、一人ひとりのがんの特徴にあったより効果の高い治療を提供することを目指す。日本のがんゲノム医療では、これまでの研究からがんとの関係性が明らかな数百規模の遺伝子のゲノム配列を調べられる「遺伝子パネル検査」が使われている――が、ヒトには約2万1千個の遺伝子があるため、全ての遺伝子は調べられていないことになる。
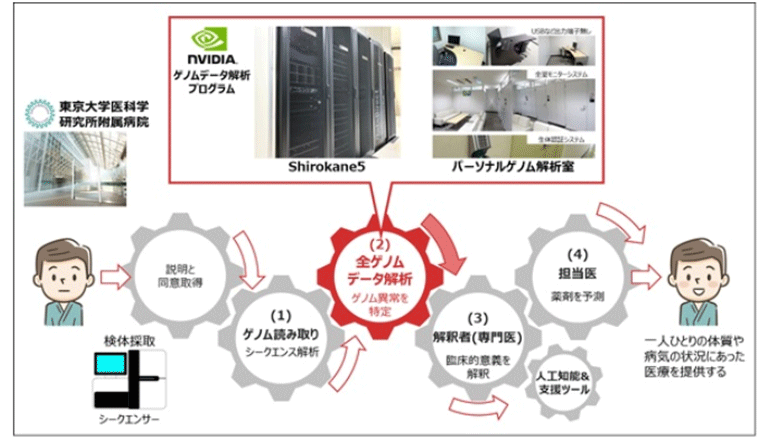
全遺伝子を調べたとしても、それらの占める割合は全ゲノム領域の2%程度に過ぎず、不明領域が膨大に存在する。近年、最先端のゲノム研究によって、遺伝子以外のゲノム領域に生じた変異もがんの原因となることが明らかに。ゆえに将来のがんゲノム医療には、全ゲノム情報の解析が必須となる。大型計算機を使っても膨大な時間がかかる、全ゲノム情報に基づく医療を多くの患者に提供するための情報解析基盤の構築が課題だという。
東京大学医科学研究所のヒトゲノム解析センターは、日立製作所の協力のもと、最新型のヒトゲノム解析用スーパーコンピュータShirokane5を用いて、がんゲノム医療における全ゲノムデータ解析の高速化・解析時間の短縮化に向けた検証を実施し、これまで10時間以上を要していた解析時間を最短1時間45分に――従来比で約80%削減することに成功した。
これにより、同センターは、個人のヒトゲノムの特徴に応じたがんや生活習慣病などの予防・診断・治療法の研究を加速し、Society5.0時代のゲノム情報を活用した個別化医療の実現を支援していくという。