
世界最高クラスの棋士に勝利して一躍名をはせた。AI技術の一つディープラーニング(深層学習)は近ごろ画像・音声認識を軸に、産業、医療、社会インフラにいたる幅広い分野で活用されつつある。
ものづくり分野では、製品の外観検査において熟練検査員の代わりにそれを用いたいとの要望がある。カメラ画像の認識では、不良品データを学習する必要がある。発生頻度の低い不良品を大量に得ることは難しく、同データの収集や不良品を模擬したデータ作成には多大な時間とコストを要する。そこで従来、データ拡張――学習データを意図的に加工・変形させることでデータ量を人工的に増やす手法が用いられていた。
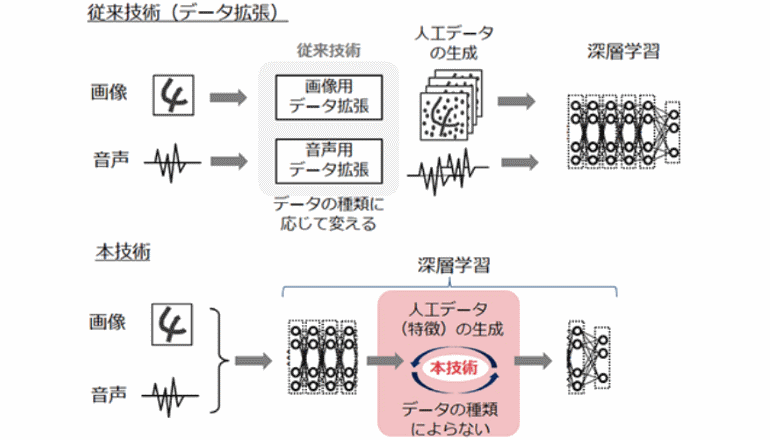
識別精度の向上には、識別の難しいデータをより多く学習することが有効であり、学習に適した質の良いデータを十分に確保することが重要である。が従来手法では、識別精度を高める効果的な学習データの生成までには至っていなかった。そのうえ、対象のデータ種類に応じて専門家がデータの増やし方を調整する必要があるため、様々な種類のデータへ短期間に適用することが困難であったという。
NECは、従来の半分程度の学習データ量でも高い識別精度を維持できるディープラーニング技術を新たに開発した。同技術は、ニューラルネットワーク(脳神経回路網モデル)の中間層で得られる特徴量を意図的に変化させることで、識別困難な学習データを集中的に人工生成。ディープラーニングに要する学習データ量をおよそ1/2に削減し、ディープラーニングを用いるシステムの開発期間短縮に貢献する。
今回の技術は、データの種類を問わず汎用的に適用可能であり、専門家による調整を不要とする。これまで学習データ収集時間やコストの高さが阻んでいた製品外観検査やインフラ保全などの領域で、AI活用システムの早期立ち上げを可能にする。成果はニューラルネットワークの国際会議「IJCNN2019」にて発表された。