
近年、深層学習により製造装置や生産品のデータを分析し、生産性を改善する試みが広まっている。例えば、良品と不良品を深層学習で自動分類する場合、一般的にはあらかじめデータに対して良品か不良品かという人間の判断を人手で付与する教示作業(教師あり学習)が必要になる。高精度な自動分類を実現するには多量のデータを教示する必要があり、作業に時間がかかることから、深層学習をはじめとする機械学習を導入することが難しいという課題があった。
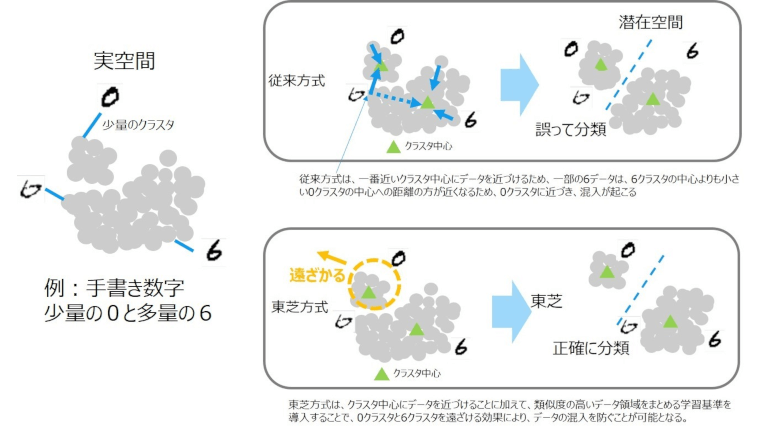
教師なし学習の一種であるクラスタリング技術は、データ間の距離や類似度といった基準に基づいてデータを所定の数のグループ(クラスタ)に分類する。少量のクラスタでは、クラスタ中心からデータまでの距離が短いため、クラスタの外にあるデータもクラスタ中心に近いとして分類してしまう。その結果、従来のクラスタリング技術では、良品に対して不良品の数が少ない場合、少量のデータ群(不良品)に他の多くのデータ(良品)が混入してしまい、十分な分類精度が得られなかった。
今回東芝が新たに開発した深層クラスタリング技術は、クラスタの中心にデータ群が集まる従来の学習基準に加え、類似度の高いデータ同士が離れなくなるような独自の学習基準を導入している。これにより、少量のデータ群が他のデータに混入することを抑制し、少量のデータ群を独立したクラスタとして分類することが可能になったという。この技術を使用し、世界共通の手書き数字の公開データを分類したところ、教師なし学習での分類精度が従来の93.8%から98.4%に向上し、世界トップレベルの分類精度を達成したと説明する。
東芝では、この技術を東芝デバイス&ストレージの半導体工場に適用する予定。また今後、社内外において半導体以外の分野を含めた製造現場への適用拡大を目指す計画。