
ヒトや動物は生命維持や子孫繁栄のため、外界の状況に応じてより多くの報酬が期待できる行動を選択していると考えられている。これまでの行動実験を用いた研究では、動物に対して、食べ物などの報酬の伴う課題を課し、動物が取る行動やそれに伴う脳活動が調べられてきた。
課題中において何が動物にとって報酬となるのかは実験者が研究目的に合わせて決めていた。しかし、自由に行動している動物の場合、何を報酬として行動しているのかは全く不明だった。また脳内では、報酬はドーパミンと呼ばれる神経伝達物質によって表現されていることから、動物にとって何が報酬となっているのかを明らかにすることは、行動戦略を司る神経メカニズムの理解のためにも重要だった。
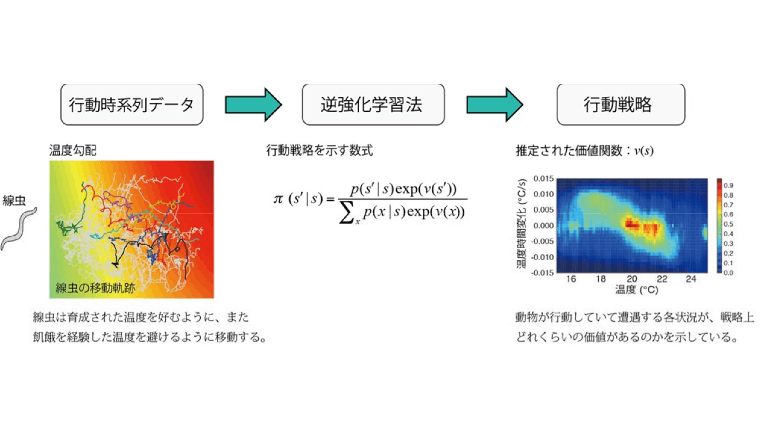
研究グループでは、動物の行動時系列データから報酬に基づく行動戦略を明らかにする機械学習法(逆強化学習法)を提案。この手法は一般的に知られる強化学習の逆問題を解くという意味で、逆強化学習と呼ばれる。強化学習では、どの状況でどれくらい報酬を得られるのかはあらかじめ決められており、試行錯誤によって得られる報酬を最大化する行動戦略を見つけ出すことが目的。一方で逆強化学習では、動物はすでに最適な行動戦略を獲得しているとして、計測された行動時系列データから未知の報酬を推定することが目的となる。
研究グループは、逆強化学習法の応用先として、シンプルなモデル動物である線虫の温度走性行動に注目。一定の温度で餌を十分に与えて成育した線虫は、その成育温度を記憶し、温度勾配(温度にムラのある空間)下では成育温度を目指して移動し、逆に一定の温度で餌のない飢餓状態で成育した線虫は、温度勾配下で成育温度から逃げて遠ざかることが知られていた。
しかし、線虫がどのような戦略にしたがって行動しているのかはこれまで解明されていなかった。線虫を温度勾配においてトラッキングすることで、行動時系列データを取得し、逆強化学習法により、線虫にとって何が報酬となっているのかを推定した。その結果、餌が十分ある状態で育った線虫は、「絶対温度」「温度の時間微分」に応じて報酬を感じていることが明らかとなった。
研究グループによると、この手法は神経活動とその表現形である行動戦略をつなぐ基盤技術を提供するもので、今後、動物の行動戦略を司る神経メカニズムの解明に貢献することが期待されるという。