
TISでは、機械学習・自然言語処理を用いた業務の生産性向上について研究・開発を進めている。その取り組みの一つとして、機械学習・自然言語処理を用いて観点に沿って情報をまとめる「観点要約」に取り組んでいる。
観点要約とは、例えば議事録であれば決定事項やTodoといった特定の「観点」に沿い文書をまとめること。文章から情報を抽出・要約する際には、まとめられた文書が「どれだけ短いか」という点より「必要な情報が抜けていないか」という点が重視される。機械学習・自然言語処理によって、「指定されたポイントを押さえて情報をまとめる」ということを実現するには、観点要約が欠かせない技術になると同社は説明する。
今回公開したchABSA-datasetは、この観点要約の研究の一貫で作成されたもの。chABSA-datasetを利用することで、「何が」良い評価・悪い評価なのかを判断する機械学習モデルの開発が可能になる。
こうしたモデルは、将来的にはマーケティングデータに対し「商品のどういった点が評価され、どういった点が不満に思われているのか」などの分析に役立つ。また、各商品を同じ観点で評価できるため、商品間の評価の比較を行う際にも活用が期待できるという。
TISでは、同様の研究を行う研究者にも活用をしてもらい、その知見を交換することを目的にchABSA-datasetを無償公開することにした。
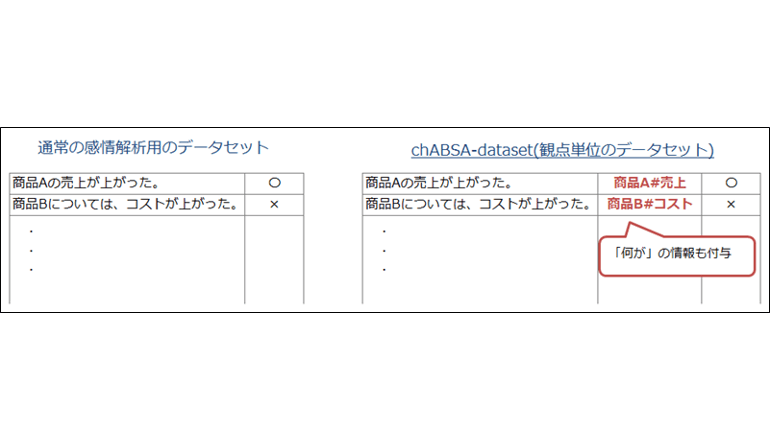
chABSA-datasetは、上場企業の有価証券報告書(2016年度)をベースに作成されたデータセット。各文に対してネガティブ、ポジティブの感情分類だけでなく、「何が」ネガティブ、ポジティブなのかという観点を表す情報が含まれている。こうした観点単位の感情分類を機械学習モデルに学習させることで、より高度な解析を支援する。
chABSA-datasetを利用した感情解析では、例えば、「商品Aの売り上げが上がった」という文について単にポジティブというだけでなく、「商品A」の「売り上げ」が「上がった」(=ポジティブ)であるということが判断できる。こうした解析結果を表形式でまとめることが可能になる。表では、緑の色が濃いほどポジティブ、灰色の色が濃いほどネガティブであることを示す。