
近年、POSデータとソーシャルメディアデータなどを組合せたマーケティング分析や、地域病院から集めた電子カルテを分析した創薬研究など、様々なデータを統合し利活用した新規ビジネス創出や新製品開発がますます重要になっている。
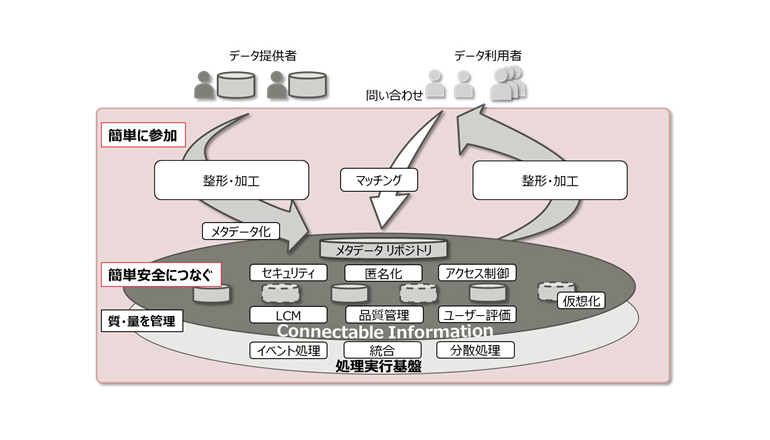
富士通研究所では、必要な様々なデータ処理技術をデータ流通・利活用の視点で体系化し「Data Bazaar(データ バザール)」と呼んで研究を進めている。このData Bazaarは、散在する様々なデータを効率的につながる形に整形・統合・分析し、抽出した価値を安心かつタイムリーに利用者に届けることで新ビジネス創出の機会へつなげるための包括的なデータ処理基盤技術群から構成される。今回、この構成要素の一つとして、データをつながる形に自動的に整形・統合する技術を開発した。
今回開発した技術では、データベース上の列(カラム)に対して、表記統一や形式統一、単位変換、不足データ結合などの様々な変換処理を適用した中間結果をそれぞれ算出し、中間結果と加工後のデータとの類似度を算出する。次に、類似度の高い中間結果を元に、さらに変換処理を適用して次の中間結果を算出し、類似度計算するという処理を繰り返しながら効率的に目的の加工後データに近づける。
これまでの変換処理と変換結果の履歴を保持して、加工後のデータに類似するデータを生成する変換処理を予測することで無駄な変換処理を削減する。富士通研究所では、加工後データを元に探索する場合と比較し、探索時間が数十分の一に短縮することを確認した。
また、目的の加工データを得るために不足しているデータセットがある場合、人手では背景知識をもとに適切なデータセットを効率よく探すことができるが、これを自動化する場合、ライブラリとして用意するなどした補助データセットの中から総当たりで調べることが必要となるため、処理時間が膨大になっていた。
今回、ライブラリとして用意しておく補助データの列ごとに、列に含まれる値の分布の特徴をメタデータとしてあらかじめ算出しておき、中間データから算出した特徴と類似度を算出することで、不足データを高速に絞り込むことを可能にした。
過去に行われた約8,000件のPOS購買データからマーケティング分析するデータセットにこの技術を適用し、今まで5日かかっていたデータ準備作業が約半日で完了させた。富士通研究所では、今後実証実験を重ねながら、変換処理の種別の拡充や補助データとしてオープンデータに対応するなどの機能拡張を進め、Data Bazaar技術を構成する機能として2018年度の実用化を目指す。