
いまメディアを騒がせ、ユーザー側でも盛んに研究され、ベンダーの開発競争が熾烈なのは人工知能(AI)技術だ。
中でもトップ級のプロ棋士に勝利した機械学習技術、ディープラーニング(深層学習)は最注目株で、総務省の「平成28年版 情報通信白書」によると、我が国の第3次人工知能ブームの背景になっている。かつてブームを牽引しつつも空白を生んだ、従来型機械学習の限界を突破するのではないかと内外で期待されている。
ディープラーニングは、膨大なデータ(ビッグデータ)からある特徴を自動抽出する表現学習という機能を持っているため、生命科学・医療分野での活用――創薬や病理診断に適している。ほかに、宇宙の成り立ちの解明、特許や論文の情報検索、音声や画像を解析し犯罪捜査などにも役立てられる。
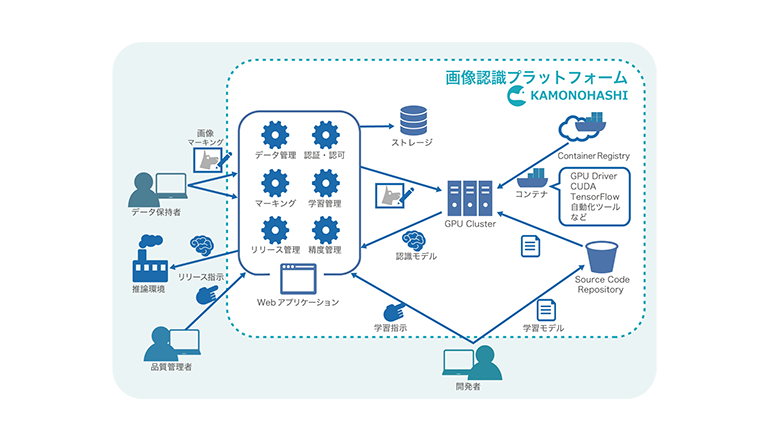
特に画像認識において従来よりもはるかに高い精度が出せることで利用が広がっている。一方で、Deep Learningを利用した画像認識アプリケーションの開発には、データの収集や管理、GPUをはじめとする莫大なコンピューティングリソースを要し、これを効率的に利用・管理するには高度なノウハウが必要とされるという。新日鉄住金ソリューションズ株式会社は、AI活用するDeep Learningを利用した画像認識アプリケーションの開発を加速させるプラットフォーム「KAMONOHASHI」を開発。これを今年度中に提供予定だと発表した。
同社の研究開発部門であるシステム研究開発センターでは、これまでにいくつかのDeep Learningを利用した画像認識アプリケーションの研究・開発に取り組んできた。そのなかで直面した問題を一つ一つ解決し、そのノウハウを凝縮したのが「KAMONOHASHI」。
リソース調達を手軽に必要な分だけ、あらゆるデータ準備作業をサポート、学習モデル作成の試行錯誤を管理、認識モデルの陳腐化を防止といった4つの特徴を備えた画像認識プラットフォームである。
KAMONOHASHIの利用により、複雑な環境構築、コンピューターリソースの確保、繰り返し発生するデータ収集、大量に発生する学習履歴の管理といった煩わしい問題から解放され、開発者がDeep Learningの学習モデル開発に集中できるとのこと。
その成果は、今月23日(火)~ 24日(水)、ザ・プリンスパークタワー東京――。日本マイクロソフト社主催の de:code2017でのセッションやNS Solutions展示ブースにて確認できる。