
情報通信
大量の時系列データを疑似アニーリング×新開発クラスタリングで分析
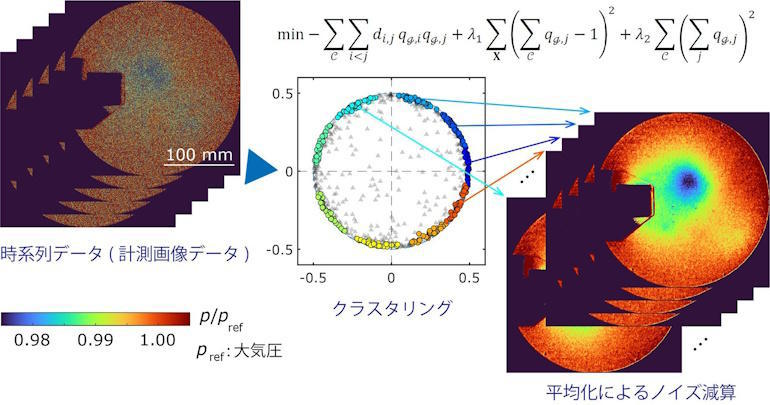
科学、工学、環境、農業、生命科学、経済学など様々な分野で時系列データが収集されている。複雑なビッグデータを適切にクラスタリング(集団化)し、特徴的な挙動を抽出し解析することがとても重要なプロセスと認識されていて、「時系列クラスタリング」の研究が盛んに行われている。
ストレージの大容量化やセンサ性能の向上が劇的に進み、画像データを扱うことも増えている昨今、巨大なデータ塊の高速クラスタリングが必要になっているという。早稲田大学理工学術院、東北大学流体科学研究所、愛知工業大学工学部の研究グループは、大サイズかつ大量の時系列データのクラスタリングを組合せ最適化問題として捉え、これに特化した計算技術を応用して高速な計算を可能とした。
どのクラスタにも相応しくない外れ値をクラスタに含まないようなアルゴリズム構築も行った。同グループは、①各クラスタに入るデータ間の類似度の和が大きくなる、②1つのデータは最大1つのクラスタに入る、③各クラスタに入るデータ数とその分散を調整する――三制約を課すクラスタリング方法を開発した。組合せ最適化問題を解くために、「富士通デジタルアニーラ」を利用した。
今回、流体計測画像を用いてクラスタリング例を実証した。同画像データは非常に大きなノイズを含んでいるが、上手くクラスタリングできることを示した。同様のケースは他の分野でも多くあり、今般発表した手法は基礎的である分、気象、生命科学、経済など応用分野が広いと考えられる。新しいコンピューティング技術の開発が活発に行われている近年、それらのコンピューティング技術を広い分野の研究に活用する視点からもインパクトが大きいと言える。
多分野での画像を含む時系列データの解析に本手法の寄与が期待されるという。研究グループの成果は、英国ネイチャーのオープンアクセス誌『Communications Engineering』に掲載された。