
我々が日常的に使っている言語をロボットなどにしゃべらせる。自然言語処理の背景には人工知能(AI)があり、AIは人間の脳神経回路網を模したしくみでの機械学習を基盤にしていて、近年、産業から医療に至るまで、さまざまな分野での応用が進み始めている。
機械学習(ML)や自然言語処理(NLP)の研究・開発では教師データが欠かせない。問題と解答をセットにしたそれは、MLモデルに正しい答えを学ばせられる。が、作成には非常に手間がかかるという。TISは、同社が公開したMLで感情解析を行うための「チャブサ・データセット」においても、その作成に多大な手間をかけた。そしてその経験を基に今月6日、「doccano(ドッカーノ)」をオープンソースソフトウェア(OSS)として公開した。
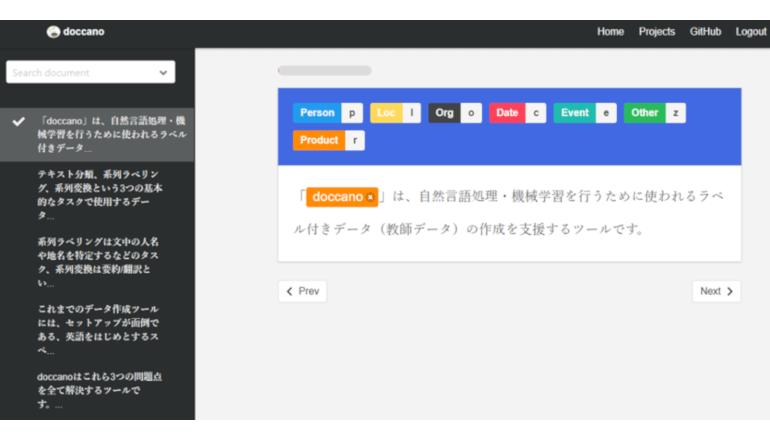
doccanoはML・NLPに使われる教師データ/ラベル付きデータの作成を容易にするアノテーションツールであり、3つの基本タスク――テキスト分類、系列ラベリング(文中の人名や地名などを特定)、系列変換(要約/翻訳)で使用するデータを作成できる。セットアップが容易であり、英語と日本語に対応しているという。
今回のツールでは、特に手間のかかる系列ラベリングを簡単にできる。テキスト分類や系列変換はExcel等の帳票ツールでも作成可能だが、系列ラベリングでは文字/単語単位でデータを作る必要があるため、帳票ツールのみでの作成は困難。そこでdoccanoを活用すれば、対象の単語を選択し、ボタンないしショートカットキーを押すだけでラベル付けができる。
ラベルの定義を明確にするなど、データ作成における本質的な難しさのサポートにはまだ改善の余地(感情解析であれば、どんな場合をネガティブ・ポジティブと判断するか等)があるという。TISは、doccanoをOSSとして公開し、より多くのフィードバックを得ることでツールの改善に活かしていく考えだ。