
FPGA能力を最大化、Hadoopデータ分析を100倍速に
膨大なデータを分析するしくみとして、Apacheソフトウェア財団の分散処理基盤「Hadoop」が注目されている。これはオープンソースのソフトウェアフレームワークであり、大規模データセットを数千ノード(≒プロセッサ)上に展開して検索や演算などをする。ファイルシステムは独自のもの(HDFS)だけでなく、AmazonやMicrosoft、OpenStackやFTP/HTTPS等経由でアクセスできるものもサポートしている。
一方、製造/物流/小売/金融/通信およびそれらのサービスを手掛ける企業では、ビッグデータを自社あるいは契約先のデータセンタで蓄積し処理する。当該データセンタでは、処理速度を上げるために多数のサーバを必要とし、周辺機器を含めたシステムへの投資や管理コストの膨張が課題になっている。そこで近年、x86に代表される一般的なサーバ用CPUに代えて、フィールドでプログラミングが可能なプロセッサ「FPGA」を採用する動きが広がっている。CPUよりもコストを抑えてシステムを構築し運用できるために。
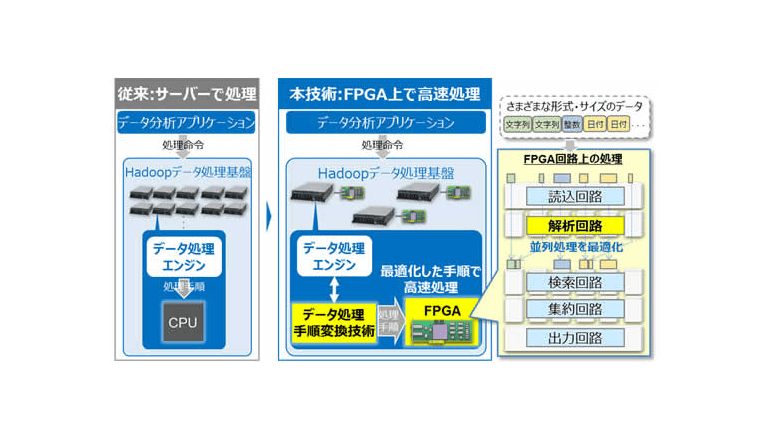
だが、FPGAは、CPUを前提に最適化されているHadoopデータ処理エンジンとの相性が悪い。
データの取得・検索・演算といった処理手順をそのまま実行しても、ハードウェアが得意とする並列処理による高速化の効果を十分に生かすことができないという。日立製作所はきょう、Hadoopデータ処理基盤で行うビッグデータ分析を、最大100倍に高速化する技術を開発したと発表した。
同社は昨年すでに「FPGAを用いた高速データ処理技術を開発」していて、今回、Hadoopに狙いを定め、本来はソフトウェア処理に合わせて作られているデータ処理手順を、ハードウェア上の並列処理に適した手順に変換した上で、さまざまな形式のデータをFPGA上で高速に処理することを可能にした。このたびの技術は、さまざまなデータの形式を解析してFPGAで高速に処理する回路設計といった特長も備えている。
大量かつ多様なデータを、さまざまな視点や条件でインタラクティブに分析して業務やサービスへ適時反映させる、ビッグデータ分析/データアナリティクスでの活用が期待される。システム機器や管理コストの増大を抑えられるだろう。技術の成果は今週、米国デンバーで開催の「SC17(The International Conference for High Performance Computing, Networking, Storage and Analysis)」にて披露される予定だ。